Essential Insights from Week 1 of the AI Builders Summit: Unpacking LLM Innovations
We have successfully completed the first week of our inaugural AI Builders Summit! With a tremendous global audience joining us virtually, our expert instructors demonstrated the art of building, assessing, and leveraging large language models. Below is a summary of this week’s sessions, and if you feel like you missed out, don’t worry! You can still register for the upcoming weeks of the month-long AI Builders Summit and access these sessions on-demand.
Transforming Enterprise AI with Small Language Models
Julien Simon, Chief Evangelist at Arcee.ai
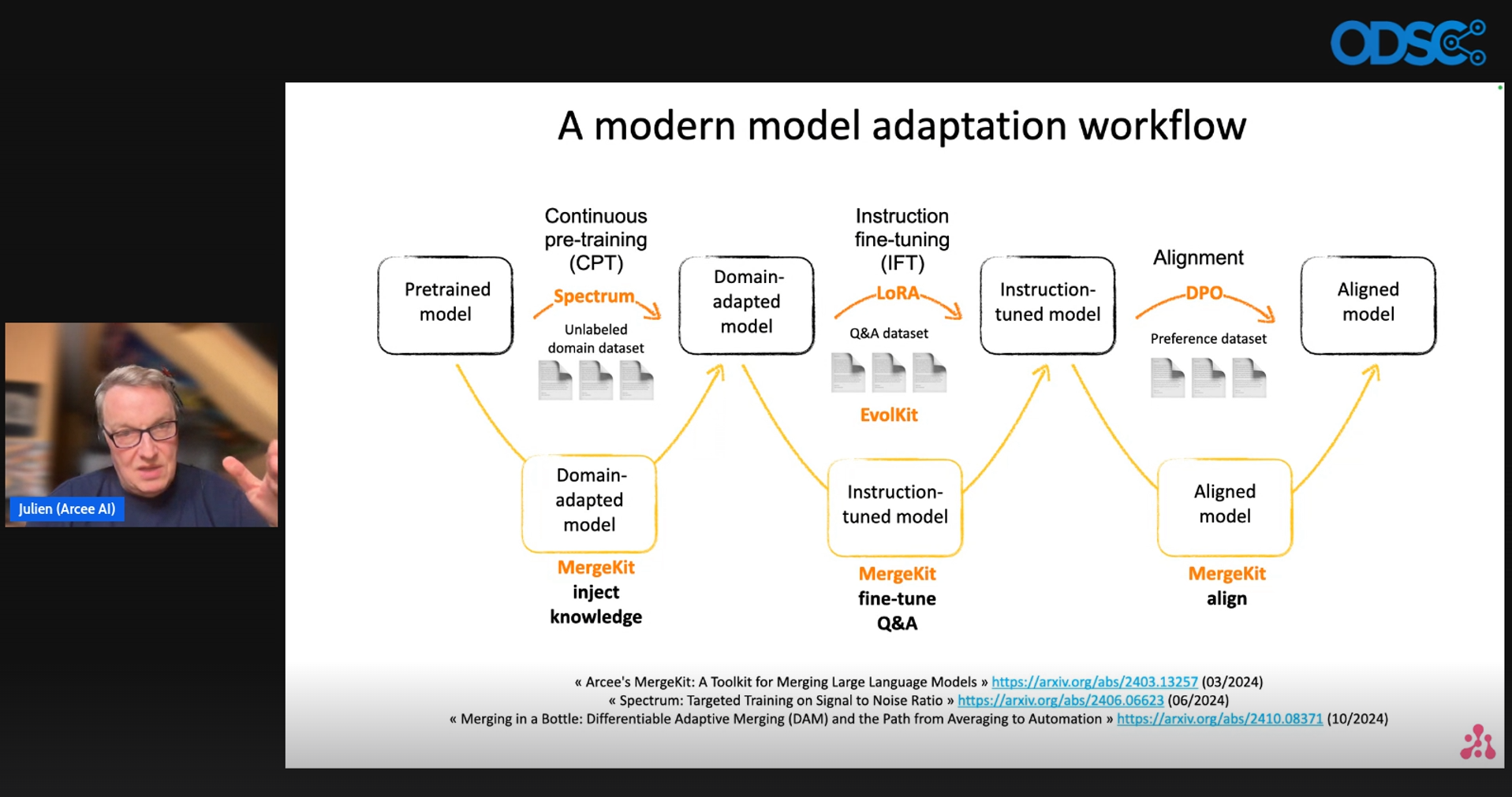
The opening session featured Julien Simon from Arcee.AI. He elaborated on crafting cost-effective and high-performance AI workflows using small language models. Julien explored various techniques, including model distillation and merging, to develop custom, efficient models. Through live coding demonstrations, he illustrated these strategies and their practical applications in enterprise environments. The session highlighted how small open-source models can excel beyond large closed models in terms of accuracy and cost-effectiveness, while emphasizing the importance of hands-on experience with the provided tools and resources.
Fine-tune Your Own Open-Source SLMs
Devvret Rishi, CEO of Predibase, and Chloe Leung, ML Solutions Architect of Predibase
In this engaging video session from the AI Builder Summit, Dev and Chloe from Predibase shared insights on effectively fine-tuning and deploying bespoke AI models utilizing their platform. The presentation was structured into two segments: a theoretical foundation followed by a practical workshop. Dev examined the motivations, challenges, and solutions offered by Predibase, highlighting the advantages of fine-tuning small, task-specific language models through Low-Rank Adaptation (LoRa) techniques and introduced TurboLoRa for enhanced performance. The session also delved into deploying models via shared and private serverless deployments on their platform while introducing advanced optimizations like FPA quantization. Chloe guided an in-depth tutorial on leveraging the Predibase user interface and Python SDK for fine-tuning models and applying these enhancements.
Building High Accuracy LLMs using a Mixture of Memory Experts
Ryan Compton, Solutions Engineer at Lamini
Ryan presented an insightful talk on constructing high-accuracy large language models (LLMs) employing a technique called Mixture of Memory Experts (MoME). Participants were introduced to Lamini and its dedication to precision in LLMs across various sectors. Ryan described how MoME integrates existing toolkits to boost performance. The discussion included technical aspects such as tuning strategies for LLMs, the architecture of Lamini’s solutions, and practical examples that featured an interactive coding demonstration to showcase the effectiveness of memory tuning and inference. He walked through the evaluation pipeline for refining models using Python SDK and REST APIs.
Evaluation-Driven Development: Best Practices and Pitfalls when building with AI
Raza Habib, CEO and Cofounder of HumanLoop
Raza Habib from HumanLoop illuminated the concept of evaluation-driven development within AI. He stressed the significance of centering evaluation in AI development and outlined three essential practices: regular data inspection, thorough logging, and involving domain experts. Raza detailed the workflow necessary for successful evaluation-driven development, which includes establishing an end-to-end pipeline, utilizing LLMs as evaluators, and the critical role of human feedback in model alignment. He illustrated this through a practical example using a RAG-based QA system, promoting continuous improvement balanced between rapid, code-driven assertions and thorough evaluations via LLMs and human reviewers to ensure sound AI development and ongoing monitoring in production environments.
Cracking the Code: How to Choose the Right LLMs Model for Your Project
Ivan Lee, CEO and Founder of Datasaur
In the concluding session of week 1, Ivan provided a detailed guide on how to select and implement the most suitable LLM for your project. This session examined Datasaur’s offerings for model evaluation, fine-tuning, and deployment. Ivan addressed the challenges in comparing models like OpenAI’s GPT 4.0, LLAMA, and Gemini, shedding light on crucial aspects such as cost, speed, and accuracy in real-world applications. He demonstrated the process of creating a sandbox environment to test various models, deploy them using APIs, and effectively fine-tune them to align with specific project needs. Furthermore, Ivan shared insights on automated and manual evaluation metrics that ensure the model’s performance meets organizational standards, while also touching on responsible AI practices and implementing guardrails to guarantee data privacy and security.
Week 2 – RAG
On January 22nd and 23rd, the focus will shift to RAG during the AI Builders Summit! The upcoming sessions will include:
- Database Patterns for RAG: Single Collections vs Multi-tenancy
- Inside multimodal RAG
- Secure Your RAG Pipelines with Fine-Grained Authorization
- Evaluating Retrieval-Augmented Generation and LLM-as-a-Judge Methodologies
- From Reviews to Insights: RAG and Structured Generation in Practice
Don’t miss out! Register now to be part of the next weeks of the virtual summit and catch the previous week’s LLM sessions on-demand. If you’re interested in further hands-on AI training, consider registering for ODSC East taking place from May 13th-15th, where you’ll also gain access to the AI Builders Summit!
Lamini’s offerings showcase practical solutions and examples, complete with an interactive coding demonstration that highlights the power of memory tuning and inference. The discussion also clarified the processes involved in assessing and improving models using both Python SDK and REST APIs.
Evaluation-Driven Development: Best Practices and Pitfalls when Building with AI
Raza Habib, CEO and Cofounder of HumanLoop
Raza Habib of HumanLoop emphasized the crucial role of evaluation-driven development in AI projects. He elaborated on the necessity of making evaluation a focal point during AI development. Raza identified three essential practices: consistent data reviews, comprehensive logging, and the importance of involving domain experts. He presented a thorough workflow for effective evaluation-driven development, which includes establishing an end-to-end pipeline, utilizing LLMs as evaluators, and the critical need for human feedback to ensure model alignment. Raza provided a practical illustration through a RAG-based QA system, reinforcing the value of iterative improvement that balances quick testing and detailed assessments using both LLMs and human reviewers. This approach fosters resilient AI development and ongoing performance oversight in production environments.
Cracking the Code: How to Choose the Right LLM Model for Your Project
Ivan Lee, CEO and Founder of Datasaur
In the final session of the first week, Ivan presented an in-depth guide on how to effectively select and deploy the most suitable LLM for your project needs. The session delved into Datasaur’s functionalities regarding model evaluation, fine-tuning, and deployment strategies. Ivan tackled the challenges of comparing various models, including OpenAI’s GPT 4.0, LLAMA, and Gemini, with a focus on key real-world factors such as cost, speed, and accuracy.
He demonstrated the process of establishing a sandbox environment to test multiple models, deploying them via APIs, and fine-tuning to align with specific project requirements. Additionally, Ivan introduced both automated and manual evaluation metrics to ensure that the model’s performance meets organizational standards. This discussion also highlighted responsible AI practices, including the implementation of safeguards for data privacy and security.
Week 2 – RAG
On January 22nd and 23rd, we are set to dive deeper into RAG during the AI Builders Summit! Upcoming sessions include:
- Database Patterns for RAG: Single Collections vs Multi-Tenancy
- Inside Multimodal RAG
- Secure Your RAG Pipelines with Fine-Grained Authorization
- Evaluating Retrieval-Augmented Generation and LLM-as-a-Judge Methodologies
- From Reviews to Insights: RAG and Structured Generation in Practice
Don’t miss out on this opportunity—register now to experience the remaining sessions of the virtual summit and access this week’s LLM discussions on-demand! If you’re eager for even more extensive AI training, consider registering for ODSC East from May 13th to 15th to gain complimentary access to the AI Builders Summit!