Essential Insights from Week 2 of the AI Builders Summit: RAG Highlights
We have successfully completed week 2 of our inaugural AI Builders Summit! With hundreds of participants joining us virtually from various corners of the globe, our exceptional instructors showcased methods to construct, assess, and maximize the potential of large language models. Below is a summary of each session from this week. If you think you’ve missed out, don’t worry! You can still join us for the upcoming weeks of this month-long AI Builders Summit and gain access to session recordings on-demand.
Database Patterns for RAG: Single Collections vs Multi-tenancy
Presented by: JP Hwang, Technical Curriculum Developer at Weaviate
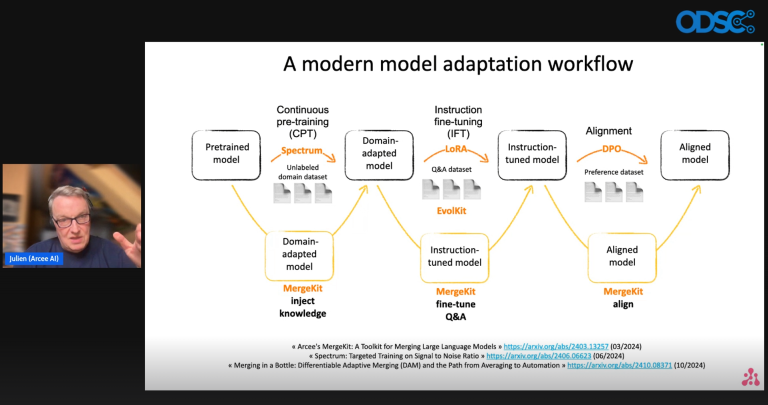
Retrieval-Augmented Generation (RAG) significantly boosts the capability of LLMs by anchoring their outputs with external data. This innovative hybrid strategy resolves drawbacks such as outdated or incomplete model knowledge, proving to be a transformative solution for applications necessitating current information. The single collection model is especially fitting for environments where all users access a shared dataset. It utilizes an object store to contain raw objects, like text documents, while employing indexes for quick and efficient searches, either inverted or vector-based.
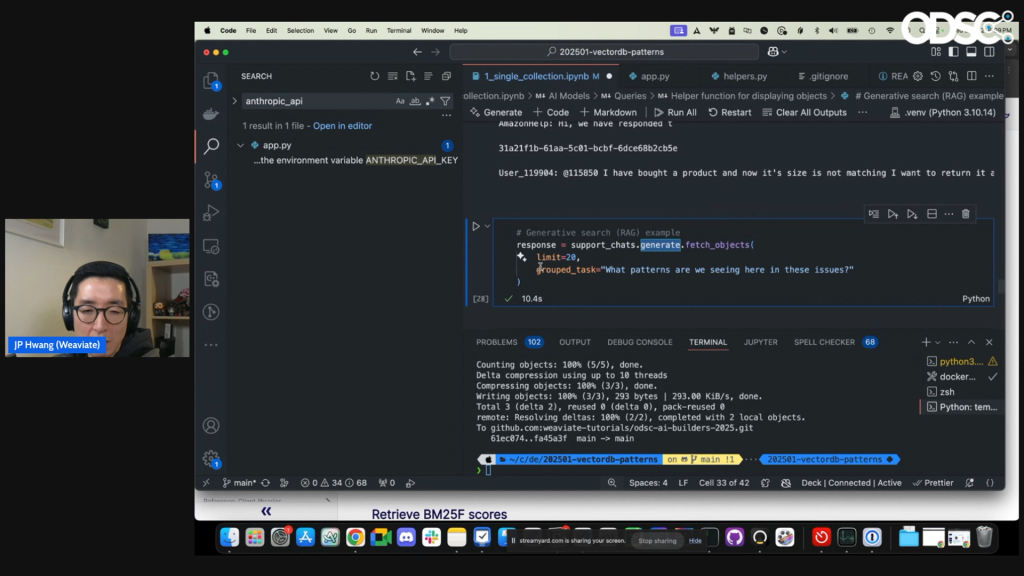
During the interactive workshop, attendees established a vector database using Weaviate, configured embeddings via tools such as Cohere and Ollama, and developed a RAG application to analyze a dataset of 50,000 customer service interactions. They tackled tasks including semantic searches for patterns (e.g., “return processes”) and implemented hybrid queries that merged vector and traditional search methodologies. A major focus was on strategies for effectively scaling vector databases, utilizing techniques like vector caching and quantization to minimize memory needs without sacrificing accuracy.
Inside Multimodal RAG
Presented by: Suman Debnath, Principal AI/ML Advocate at Amazon Web Services
The multi-tenancy approach is crafted for use cases where data privacy and isolation are vital, such as SaaS platforms or applications managing sensitive data. Each tenant’s data is stored independently, thus ensuring security, regulatory compliance, and efficient resource usage. This structure mitigates risks of unintended queries or data leaks and lessens the overhead associated with accessing extensive shared datasets.
Participants successfully configured a multi-tenant vector database by activating multi-tenancy in Weaviate and simulating a SaaS scenario with isolated datasets for five distinct customers. This setup enabled them to execute tenant-specific RAG workflows while preserving tight data privacy controls. Use cases for this architecture include examining private datasets like customer support tickets or managing sensitive information within sectors such as healthcare and finance.
Secure Your RAG Pipelines with Fine-Grained Authorization
Presented by: Sohan Maheshwar, Lead Developer Advocate at authzed.com
Evan Corkrean, Sr. Solutions Engineer at authzed.com
The speakers presented two methodologies for incorporating authorization into RAG workflows. The first approach, post-filter authorization, entails embedding metadata within vector databases to verify user permissions after data retrieval. The second approach, pre-filter authorization, proactively consults an authorization system before accessing vector databases to filter out unauthorized embeddings. Both strategies strike a balance between security and performance, with pre-filtering particularly advantageous in contexts demanding stringent access control.
Participants developed a secure RAG pipeline employing SpiceDB, Pinecone, and OpenAI. They constructed a ReBAC schema, enriched embeddings with metadata, and showcased access control measures. Unauthorized users, for instance, were prevented from obtaining embeddings associated with restricted documents, thus ensuring adherence to data privacy regulations.
Evaluating Retrieval-Augmented Generation and LLM-as-a-Judge Methodologies
Presented by: Stefan Webb, Developer Advocate at Zilliz
Stefan shared insights on the role of LLMs as evaluators for RAG systems. He underscored the significance of evaluation in assuring the quality and dependability of RAG pipelines, while promoting scalable approaches for thorough assessments.
Webb introduced the innovative concept of using LLMs as judges, enabling the evaluation of RAG outputs without the necessity for ground truths. Among the techniques discussed were pairwise response comparisons and scoring based on dimensions such as faithfulness, relevance, and accuracy. Nevertheless, challenges like positional and verbosity biases can influence evaluation outcomes, highlighting the need for fine-tuning and bias reduction strategies. This session culminated in practical implementation through tools like Milvus and RAGAS to construct and evaluate RAG pipelines.
From Reviews to Insights: RAG and Structured Generation in Practice
Presented by: Cameron Pfiffer, Developer Relations Engineer at .txt
Cameron’s session delved into the real-world applications of RAG pipelines, particularly focusing on the transformation of unstructured data into organized insights. Attendees participated in a hands-on experience, creating modular RAG systems capable of processing both text and images.
Moreover, Bifer exhibited how to leverage vector databases such as Milvus and Hugging Face models for efficient indexing, retrieval, and re-ranking. The session emphasized streamlining retrieval processes and applying finely-tuned prompts to boost output relevance. By utilizing advanced re-ranking methods with LLMs, participants witnessed firsthand how to extract structured insights from raw reviews, demonstrating the adaptability and scalability of RAG frameworks in practical scenarios.
Week 3 – AI Agents
On January 29th and 30th, our focus will shift to AI Agents during the AI Builders Summit! The upcoming sessions will include:
- Building agentic RAG with LlamaIndex Workflows
- Modern AI Agents from A-Z: Building Agentic AI to Perform Complex Tasks
- Using World Models to Build AI Agents for Optimal Decision Making
- LLM Engineering Masterclass: Select and Apply LLMs Using RAG, Fine-tuning and Agentic AI
- Building and Evaluating Agents with LangGraph and RAG
Secure your registration now to participate in the next weeks of the virtual summit, and catch this week’s RAG sessions on-demand, along with last week’s LLM sessions! Furthermore, for those seeking even deeper hands-on AI training, register for ODSC East from May 13th-15th to gain access to the AI Builders Summit as well!
Participants tackled the challenge of querying extensive shared datasets by configuring a multi-tenant vector database utilizing Weaviate’s multi-tenancy feature. They simulated a Software as a Service (SaaS) scenario, maintaining distinct datasets for five different customers. This setup enabled the execution of tenant-specific Retrieval-Augmented Generation (RAG) workflows while ensuring rigorous data privacy. Such implementations are valuable for analyzing sensitive datasets, including customer support tickets, and managing confidential information in fields like healthcare and finance.
Secure Your RAG Pipelines with Granular Authorization
Sohan Maheshwar, Lead Developer Advocate at authzed.com, and Evan Corkrean, Sr. Solutions Engineer at authzed.com, showcased two distinct strategies to weave authorization into RAG workflows. The first approach, post-filter authorization, involves embedding relevant metadata within vector databases to assess user permissions after data retrieval. Conversely, pre-filter authorization engages an authorization system before accessing vector databases, thereby filtering out unauthorized embeddings beforehand. Both techniques effectively balance security and performance, with pre-filtering particularly advantageous in situations that demand strict access controls.
The speakers demonstrated how to implement a secure RAG pipeline leveraging SpiceDB, Pinecone, and OpenAI. They showcased the development of a Relationship-Based Access Control (ReBAC) schema, incorporated metadata into embeddings, and illustrated the nuance of access control. An example highlighted how unauthorized users were effectively blocked from accessing embeddings associated with restricted documents, thereby ensuring adherence to data privacy regulations.
Assessing RAG and LLM-as-a-Judge Methodologies
Stefan Webb, Developer Advocate at Zilliz, elaborated on the role of Large Language Models (LLMs) as evaluators for RAG systems. He underscored the necessity of evaluation processes to guarantee the quality and reliability of RAG pipelines, promoting scalable methodologies for thorough assessments. Webb introduced the innovative idea of employing LLMs as judges, thereby facilitating the evaluation of RAG outputs without the need for predefined ground truths. Methods discussed included pairwise response evaluations and scoring predicated on fidelity, relevance, and precision. However, challenges such as position and verbosity biases can influence assessments, necessitating strategies for fine-tuning and bias reduction. The session wrapped up with practical implementations utilizing tools like Milvus and RAGAS to build and assess RAG pipelines.
Transforming Reviews into Insights: RAG and Structured Generation in Action
Cameron Pfiffer, Developer Relations Engineer at .txt, engaged attendees by exploring the pragmatic uses of RAG pipelines, especially in converting unstructured data into valuable structured insights. Participants were given hands-on experience in creating flexible RAG systems capable of processing both text and images. The demonstration included using vector databases such as Milvus alongside Hugging Face models for indexing, retrieval, and advanced re-ranking techniques. Focus was placed on enhancing retrieval processes through fine-tuned prompts, leading to improved output relevance. By implementing sophisticated re-ranking strategies with LLMs, participants learned how to distill structured insights from raw reviews, highlighting the versatility and scalability of RAG implementations in various real-world contexts.
Week 3 – AI Agents
On January 29th and 30th, the AI Builders Summit will shine a spotlight on AI Agents! Upcoming sessions feature:
- Building Agentic RAG with LlamaIndex Workflows
- Comprehensive Overview of Modern AI Agents: Creating Intelligent AI to Execute Complex Tasks
- Using World Models for Optimal Decision-Making in AI Agents
- LLM Engineering Masterclass: Selection and Application of LLMs in RAG, Fine-tuning, and Agentic AI
- Constructing and Assessing Agents with LangGraph and RAG
Don’t miss out! Register now to take part in the next phases of this virtual summit and enjoy on-demand access to this week’s RAG sessions, as well as last week’s LLM discussions. For those seeking deeper, hands-on AI training, register for ODSC East set for May 13th-15th, which includes complimentary access to the AI Builders Summit!