Unlocking the Power of Splunk AI Assistant: A Comprehensive Technical Guide for SPL Aficionados
The Splunk AI Assistant for SPL (SAIAS)
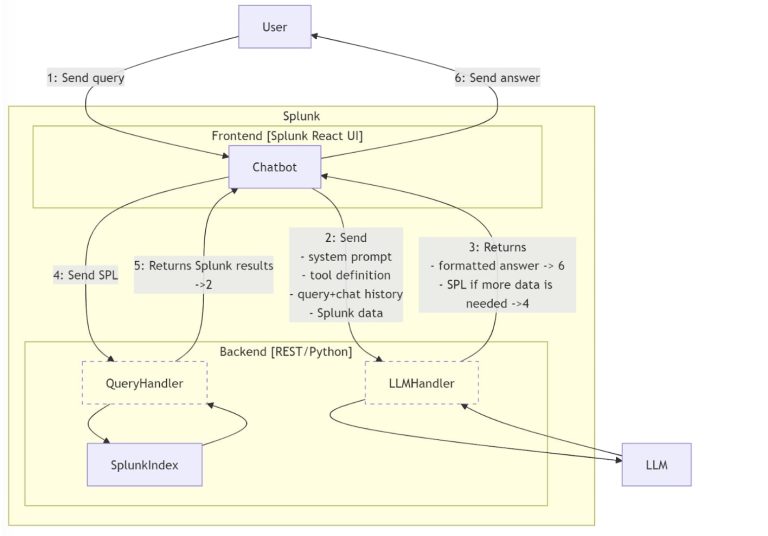
Meet the Splunk AI Assistant for SPL (SAIAS), an innovative generative AI tool designed to streamline and elevate your everyday tasks. SAIAS intuitively converts everyday language inquiries into SPL while enriching user comprehension through detailed explanations of SPL concepts and functionalities related to Splunk’s offerings. In this article, we will explore the underlying system that powers this AI model, the comprehensive safety measures in place, and the strategies employed to assess the effectiveness of the SPL generation capabilities of the system.
Solution Overview
Datasources
Our AI model is refined through a careful blend of expertly crafted data and synthetically produced information, bolstered by Splunk documentation and supporting training materials. To guarantee an extensive and varied repository of SPL examples, we systematically categorized and sampled sequences of SPL commands gathered from our SPL queries.
Retrieval Augmented Generation (RAG)
The AI Assistant utilizes a RAG-based framework to enhance model performance. A thorough database of SPL syntax, indexed in a vector database, has been developed to handle diverse scenarios in IT, observability, and security. When users submit a query, our system discerns the user’s intent, retrieves relevant past queries, and ranks these examples for presentation to the Large Language Model (LLM). Our evaluations reveal that presenting these examples to pretrained LLMs significantly improves the syntax of SPL commands, leading to enhanced readability.
Model Fine-tuning
In the last year, open-source LLMs have demonstrated remarkable reasoning capabilities relative to their parameter sizes. We analyzed various pretrained models based on their proficiency in next-token prediction for SPL completion, ultimately selecting those open-source models that incorporated SPL data during their training. Throughout the fine-tuning process, we assembled a corpus that blended synthetically generated natural language descriptions of SPL queries with diverse conversational and coding instruction datasets. Our findings indicate that the fine-tuned model, coupled with the RAG approach, significantly minimized syntax errors and eliminated references to SQL analogs, thereby enhancing execution accuracy.
Guardrails
Establishing guardrails is crucial for improving the quality, ethics, security, and adherence to AI trust principles. At this time, SAIAS incorporates three main input guardrails:
- Language Guardrail: The model identifies the language(s) used in the prompt, rejecting requests in unsupported languages. Currently, SAIAS accommodates English, French, Spanish, and Japanese.
- Gibberish Text Guardrail: This feature filters out nonsensical or incoherent input, ensuring clarity.
- Prompt Injection Guardrail: This guards against manipulative attacks, where prompts could be altered to generate harmful or unintended results.
Note: The system’s guardrails do not:
- Guarantee the accuracy of the output—generated SPL may lack efficiency, exhibit grammatical flaws, or be contextually incorrect, commonly referred to as hallucinations.
- Replace users’ acknowledgment of their responsibilities when utilizing the system.
Latency
Latency plays a pivotal role in user experience with LLMs. Factors such as chat history length, user inquiries, and RAG inputs influence latency. Results are provided in real-time, with initial tokens delivered in mere seconds. For optimal results during a single interaction, users should refine their queries. To enhance throughput, it’s advisable to initiate a new conversation once you receive the desired output to minimize context history.
Measuring Model Quality
One of the main challenges in creating an AI assistant for structured query language is maintaining a stringent accuracy standard for syntax errors while effectively capturing user intent. In evaluating the AI Assistant’s outputs, we concentrate on three primary criteria:
- Token Similarity: This metric gauges how closely the generated SPL tokens correspond with a known reference query, offering insights into the potential utility of a query, even if it cannot be executed in a specific Splunk environment, such as producing placeholders for unknown values.
- Structural Similarity: This analysis examines the organization of SPL commands between reference and candidate SPL queries, providing insight into the effectiveness and clarity of the proposed queries alongside high-quality SPL benchmarks.
- Execution Accuracy: This assesses how closely the results of an SPL query match expected outcomes when executed on the appropriate index, reflecting the LLM’s capability to generate precise SPL queries.
Model Metrics
| Model | Bleu Score | Matched Source – Index | Matching Sourcetype | Command Sequence Normalized Edit Distance (lower is better) | Execution Accuracy |
|---|---|---|---|---|---|
| GPT 4 – Turbo | 0.3135 | 2.10% | 65.10% | 0.5683 | 20.40% |
| Llama 3 70B Instruct | 0.3004 | 2.25% | 78.17% | 0.6477 | 78.40% |
| Splunk SAIA System | 0.4938 | 2.40% | 85.90% | 0.4104 | 39.30% |
Prompting Guidance
Write SPL
When crafting a query for the Assistant, it’s more effective to use commands rather than questions. Our examples are organized based on descriptive SPL queries instead of intent. Clarity is key to reduce potential miscommunication. For instance, instead of saying, ‘Find all overprovisioned instances,’ consider a more explicit directive like ‘Find all EC2 instances with less than 20 percent average CPU usage or memory utilization below 10 percent.’ This approach equips the model with essential details about the appropriate index, enabling it to produce focused responses that meet your intended query structure. Additionally, ensure to specify indices, source types, fields, and values using hyphens or quotes to minimize hallucinations. If you have uncertainty about the available indices, you can ask, “List available indices.” Even if the SPL structure seems correct, the model may assume certain fields or flags that may require intermediate calculations.
Explain SPL
The “Explain SPL” feature accepts any valid SPL and provides an in-depth natural language explanation of it. Be sure to enter only SPL in the prompt window. For variables, use double angle brackets ‘’.
Tell Me About (QnA)
When posing natural language questions, clarity and relevance are crucial. Avoid gibberish, nonsensical phrases, and grammatical errors to maintain the quality of the conversation. Additionally, steer clear of manipulative language that could lead to harmful or unintended outcomes, thus ensuring the integrity of the system. If any guardrails are activated, the assistant will issue an error message.
Language Support
At present, we offer responses solely in four languages: English, French, Spanish, and Japanese. Inputs in other languages will not be processed, ensuring high-quality interactions and effective system management.
Data Privacy
SAIAS collects various types of data for research and development, depending on your data sharing preferences configured during installation. Should you consent to the EULA and enable data sharing, the details of the data gathered are outlined in our data collection blog. You have the option to opt out, ceasing future data collection, while previously gathered data will remain archived.
Next Steps
The Splunk AI Assistant for SPL is now accessible on Splunkbase for the Splunk Cloud Platform hosted on AWS. To discover the benefits of the Splunk AI Assistant for SPL, explore our product blog. For comprehensive guidance on utilizing this application, refer to our documentation. Ready to dive in? Visit Splunkbase today.